基本概念:
- 非平凡前缀:包含首位字符但不包含末位字符的子串组合。
- 非平凡后缀:包含末位字符但不包含首位字符的子串组合。
- next数组定义(又称部分匹配表):模式串T j指针的变化(即当主串与模式串的某一位字符不匹配时,模式串要回退的位置)
next[j]的值:当前字符j之前(j-1位)的串的前后缀的相似度(重合字符数+1)
模式串求next数组
此教程面向的对象:
- 了解KMP算法原理,可以手写next数组
- 看过求next数组的代码,进行过相关思考
next[j]数组函数定义:
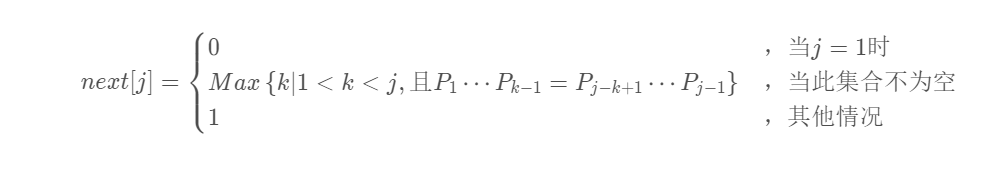
看懂求next数组代码最重要的是理解下面两句话:
next[j+1]的最大值为next[j]+1- 如果$P_{k1}\neq P_{j}$ ,那么next[j+1]可能的最大值为
next[next[j]]+1,以此类推即可高效求出next[j+1]。(重点)
第一句话的意思是,我们已知next[j]的情况下,继续与下一位字符匹配,最理想的情况就是下一位字符匹配依然相等$P_{k1}$= $P_{j}$,next[j+1]=next[j]+1,相似度+1
第二句话的意思是,我们已知next[j]的情况下,继续与下一位字符匹配,匹配不相等(next[j]只是当前字符j之前的串的前后缀的相似度,然而决定回溯跨度的是整个S串的前后缀的相似度),进行回溯,继续下一次匹配
流程:
①求next[j+1],则已知next[1]、next[2]$\cdots$next[j]
②假设next[j]=$k_1$,则有$P_1\cdots P_{k-1}$ = $P_{j-k+1}\cdots P_{j-1}$(前k1-1位字符与后k1-1位字符重合)
③如果$P_{k1}$= $P_{j}$,则$P_1\cdots P_{k-1}P_{k1}$ = $P_{j-k+1}\cdots P_{j-1}P_{j}$,则next[j+1]=k1+1,否则进入下一步
④假设next[k1]=k2,则有$P_1\cdots P_{k2-1}$ = $P_{k1-k2+1}\cdots P_{k1-1}$
⑤第二第三步联合得到:$P_1\cdots P_{k2-1}$ = $P_{k1-k2+1}\cdots P_{k1-1}$ = $P_{j-k1+1}\cdots P_{k2-k1+j-1}$ = $P_{j-k2+1}\cdots P_{j-1}$ 即四段 重合
⑥这时候,再判断如果$P_{k2}$ = $P_{j}$, 则$P_1\cdots P_{k2-1}P_{k2}$ = $P_{j-k2+1}\cdots P_{j-1}P_{j}$ ,则next[j+1]=k2+1;否则
再取next[k2]=k3…以此类推
图解:
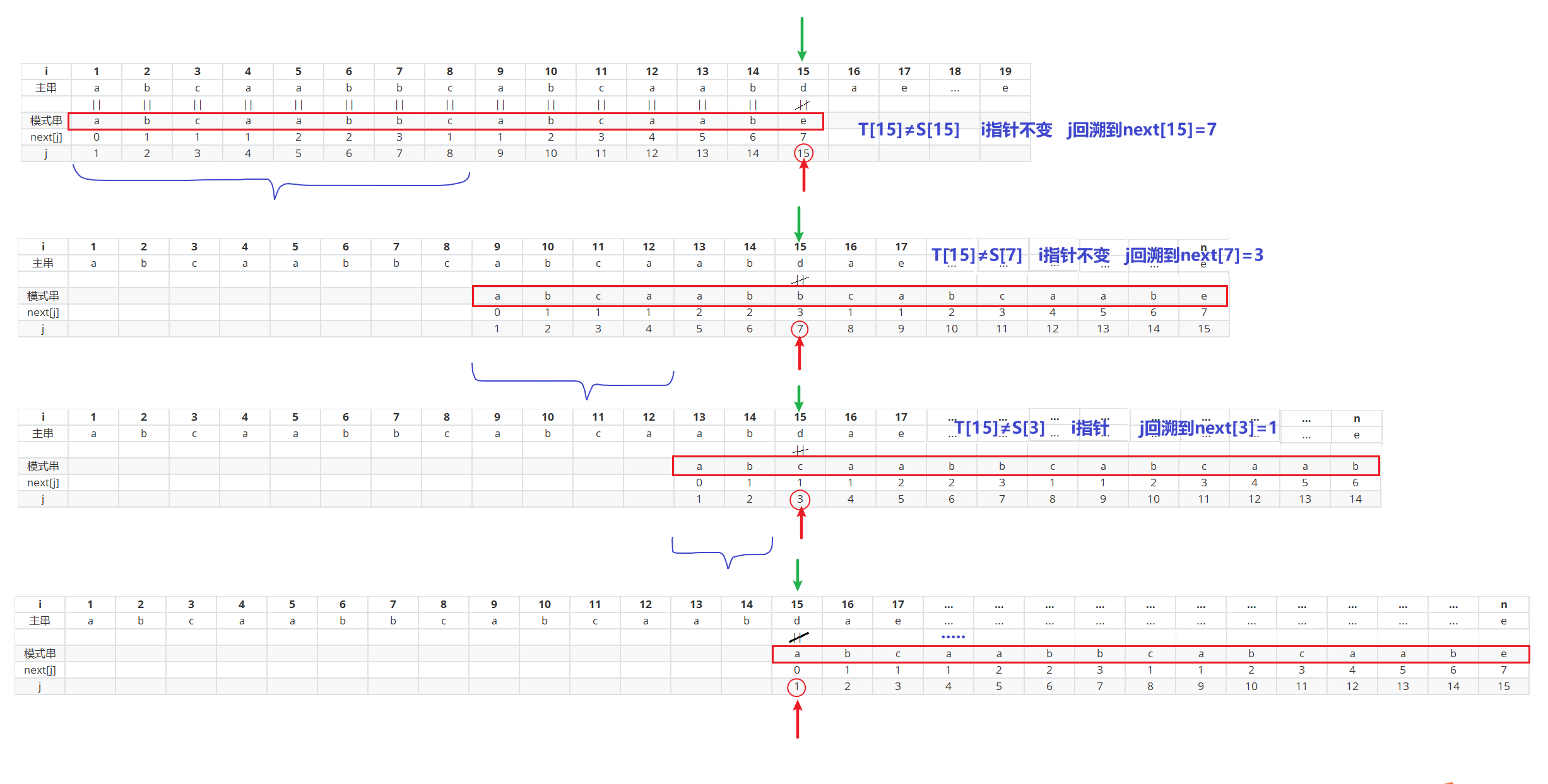
假设我们已知next[16] = 8 ,需要求next[17]
next[16] = 8 ,那么就是在j=16的字符前的串的前后缀有 8 -1 =7个字符重复
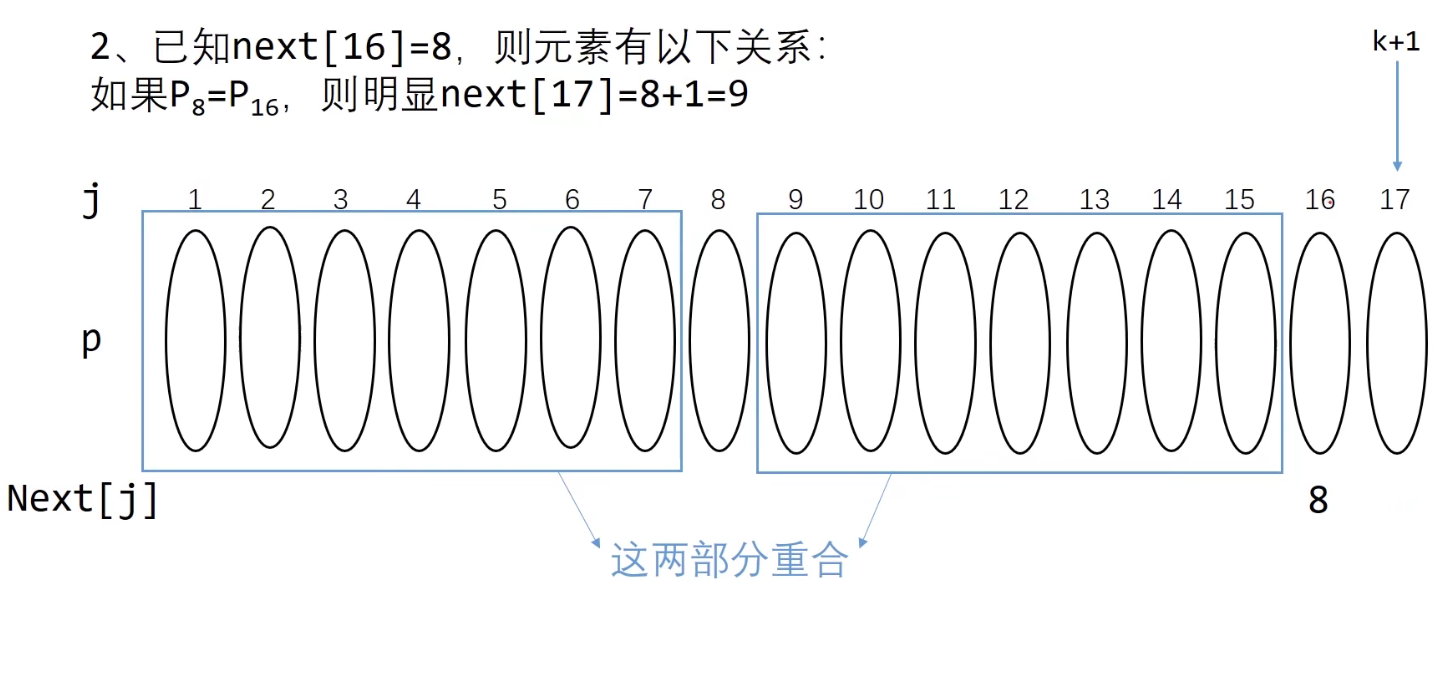
求next[17] 我们只需要比较$P_{8}$和$P_{16}$,最理想的情况就是$P_{8}$ = $P_{16}$ 那么next[17] = next[16]+1
若$P_{8}$ ≠ $P_{16}$ ,k进行回溯,回溯到next[8] (我们假设next[8] = 4)
next[8] = 4 ,那么就是在j=4的字符前的串的前后缀有 4 -1 =3个字符重复
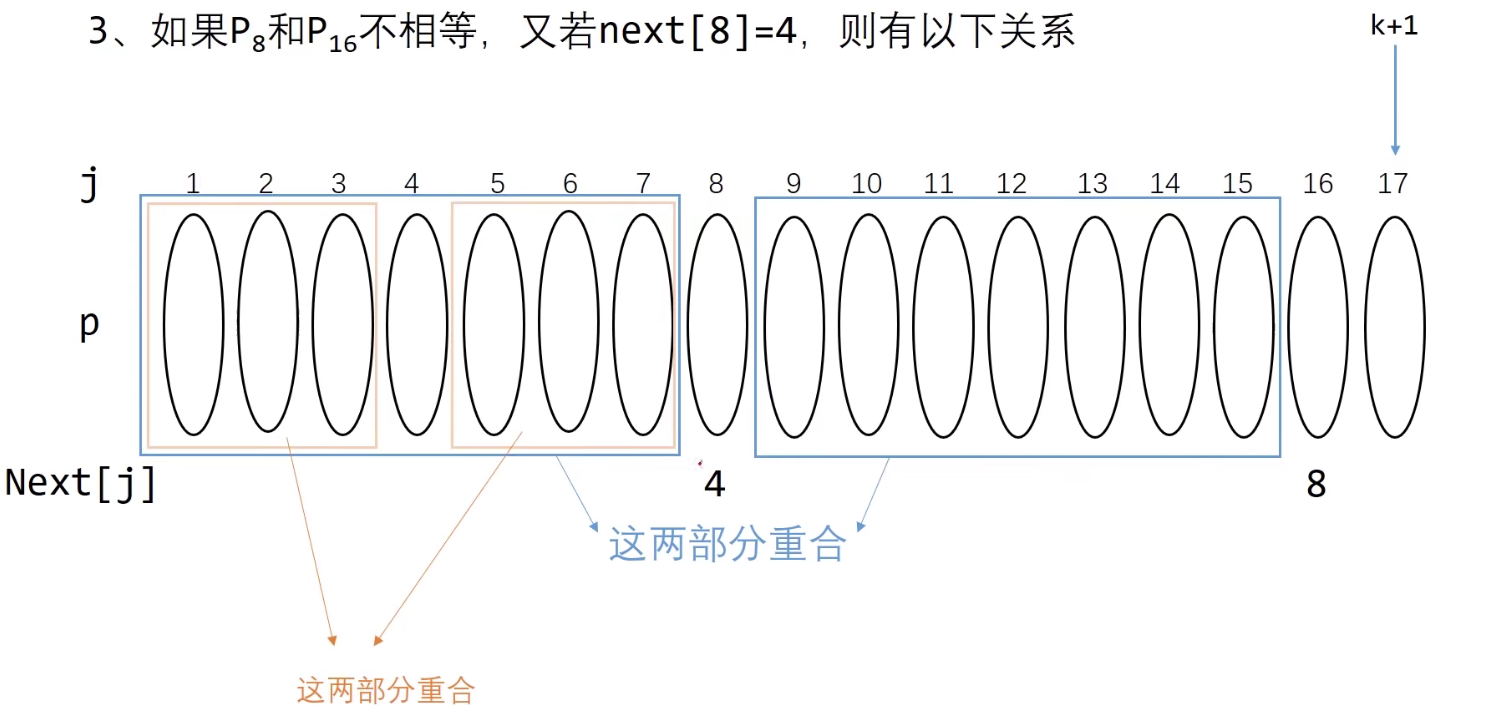
现在求next[17] 我们只需要比较$P_{4}$和$P_{16}$,第二理想情况就是$P_{4}$ = $P_{16}$ 那么next[17] = next[8]+1 = 5
为什么呢
因为蓝色部分相等,且橙色部分相等 ,那我们就可以推出四部分是相等的
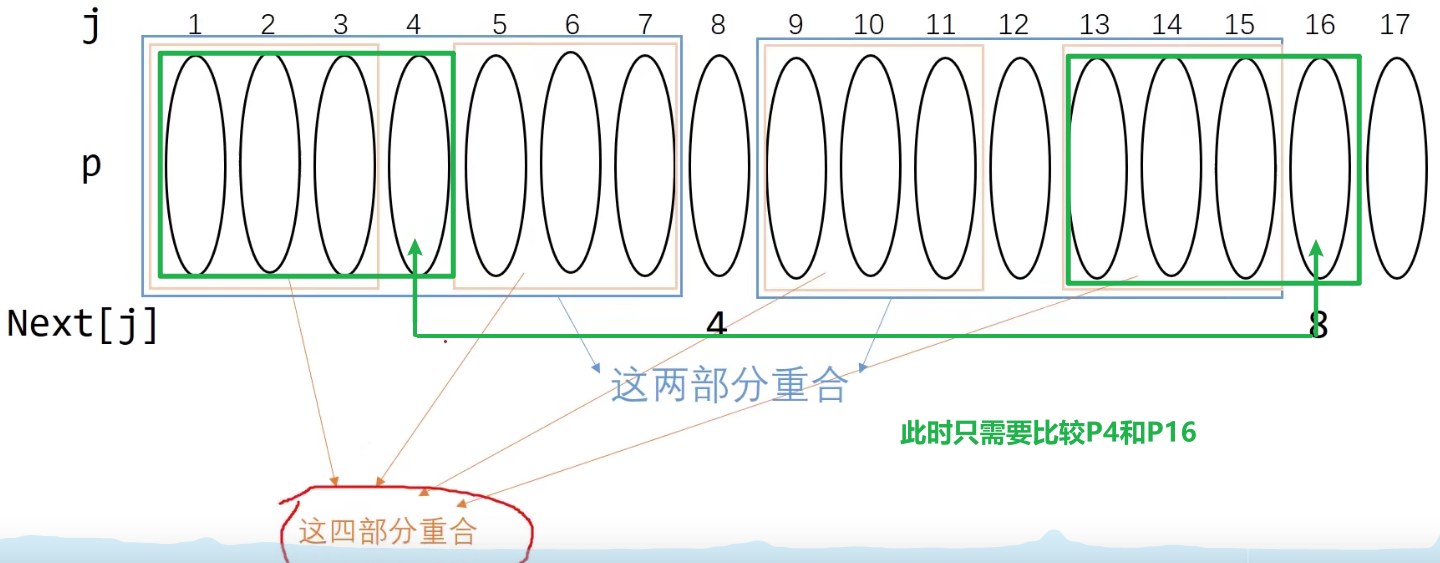
如果第二理想情况都不满足,即$P_{4}$ ≠ $P_{16}$,k继续回溯,k = next[4] (我们假设next[4] = 2)

同理,若$P_{2}$ = $P_{16}$ 那么next[17] = next[4]+1 = 3
否则,继续回溯,若回溯到next[1]=0,还不相等,则说明相似度为0,递推结束,双指针往后移一位,进行新一轮子串比较
求next数组代码
1
2
3
4
5
6
7
8
9
void getNext(string T,int* next){
int i = 1,k = 0;
next[1] = 0;
//T[0]代表模式串T的长度
while(i < T[0]){
if(k == 0 || T[i] == T[k]) next[++i] = ++k; //字符相同继续比较
else k = next[k]; //若字符不相同 k指针回溯
}
}
举个例子:
模式串:ababac
先用一个例子来看代码的运行流程
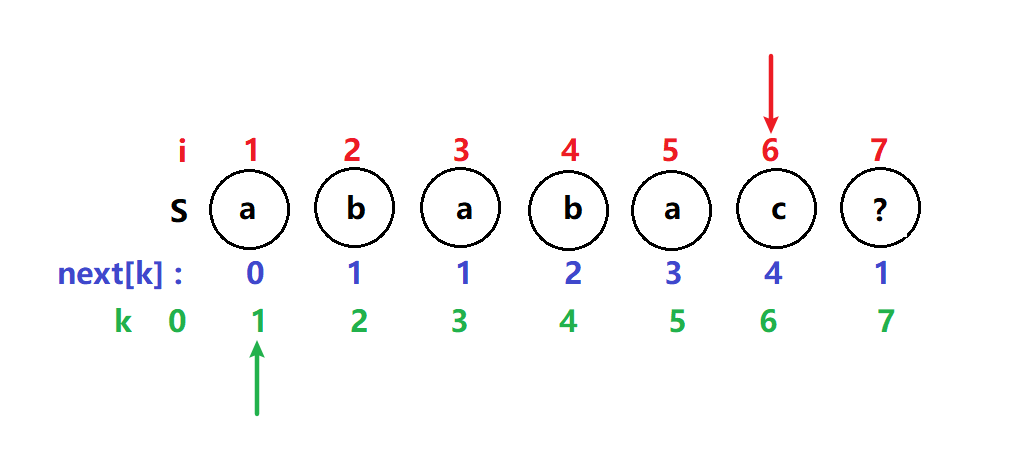
开始i指针指向1,k指针指向0,只有一个指针指向了字符,至少需要两个字符才能比较, 进入第一个if满足k == 0,next[++i] =++k,
i,k指针都向前移一位
next[2] = 1;即j=2,在j之前只有一个字符,所以前后缀相似度为1
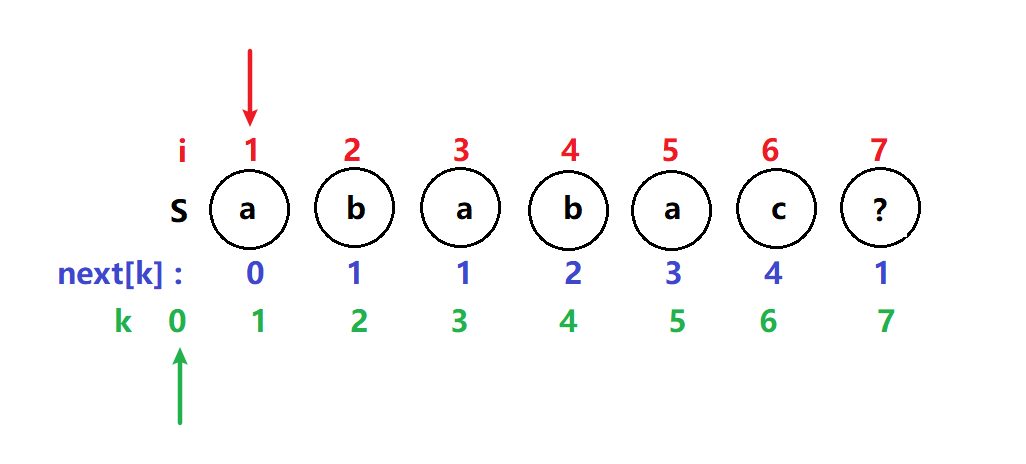
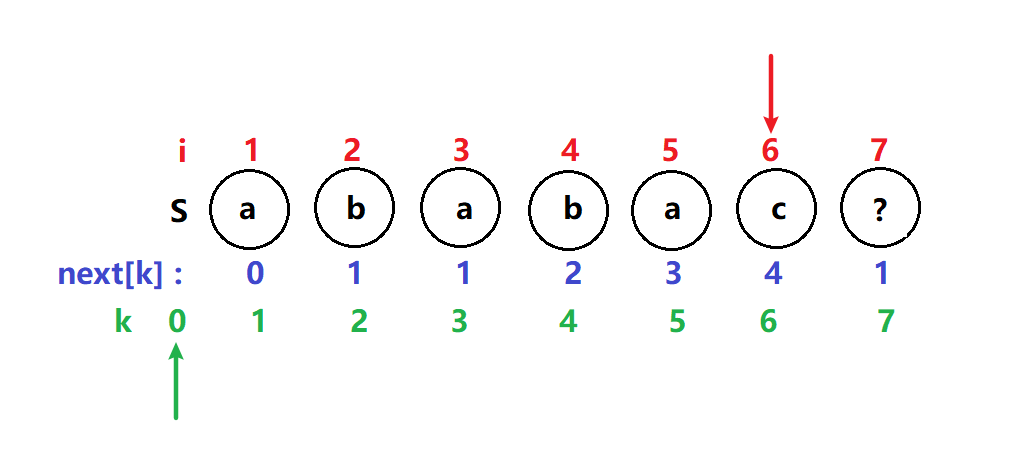
i = 2 ,k = 1 T[2]不等于T[1] k指针回溯到next[k] 即next[1] = 0 ;
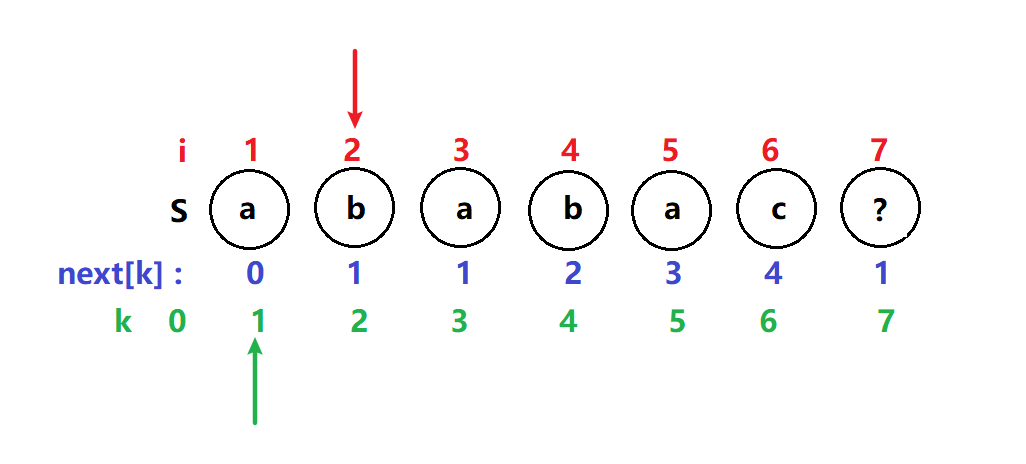
此时k又等于0了 满足if i,k指针都向前移一位,比较下一位
next[3] = 1
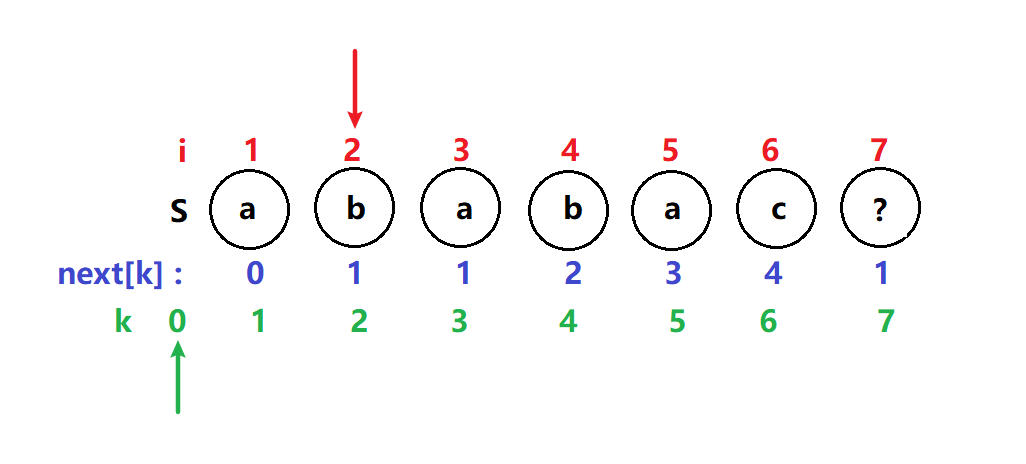
i = 3 , k = 1 T[3] = T[1] 满足if i ,k 指针继续后移
next[4] = 2
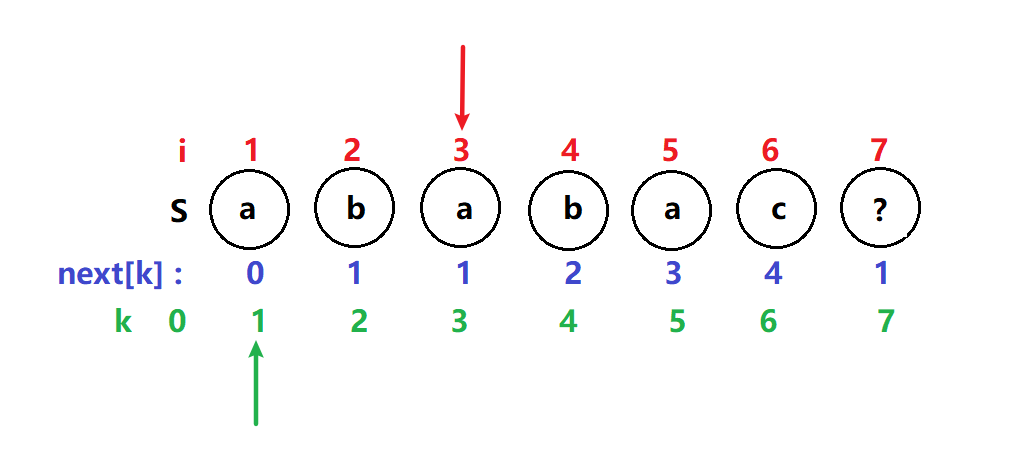
i = 4 ,k = 2 T[4] = T[2] 满足if i,k指针继续后移
next[5] = 3
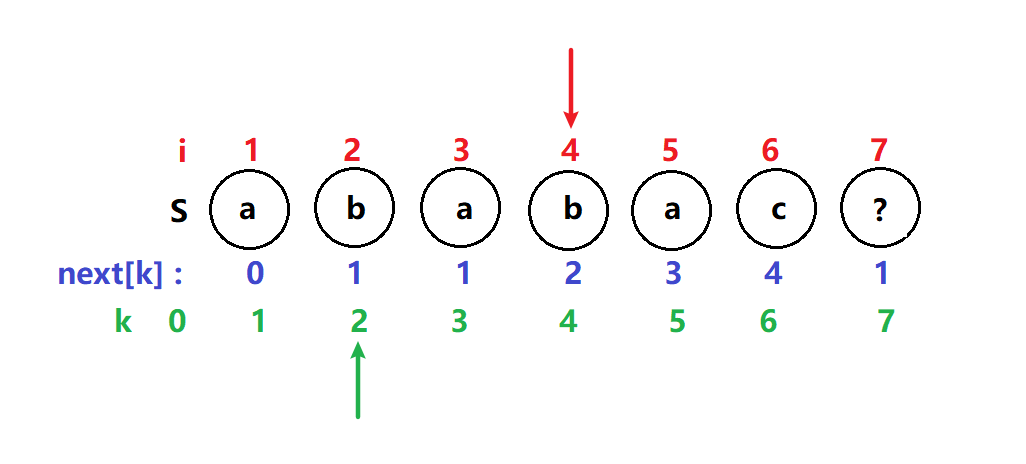
i = 5,k = 3 T[5] = T[3] 满足if i,k指针继续后移
next[6] = 4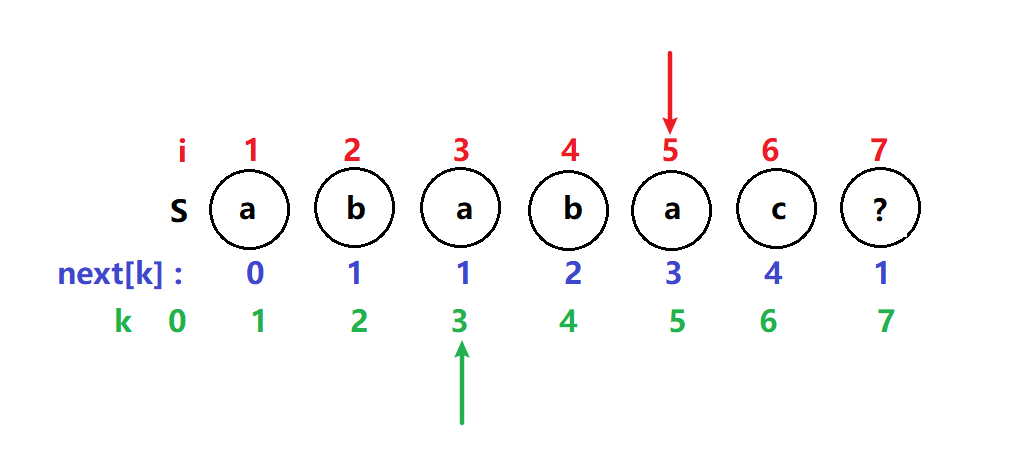
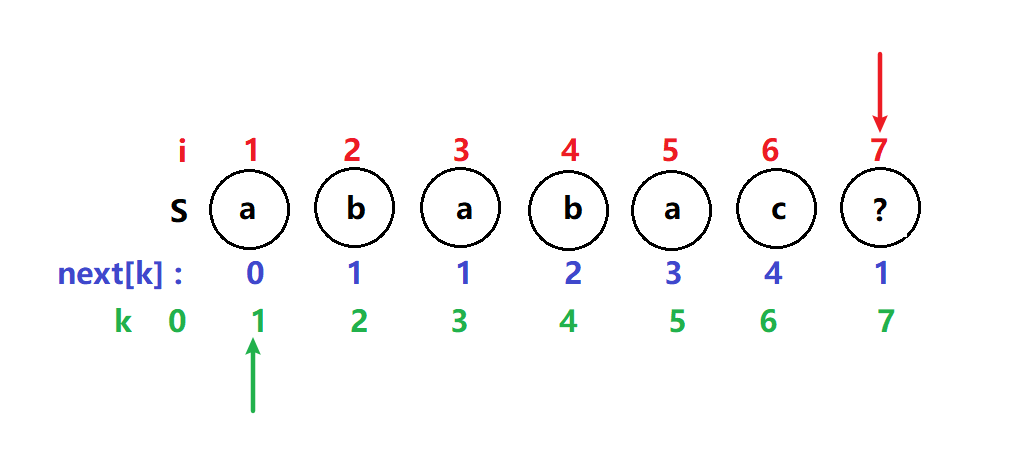
i = 6,k = 4 T[6] ≠ T[4] k指针开始回溯到next[k] =next[4] = 2
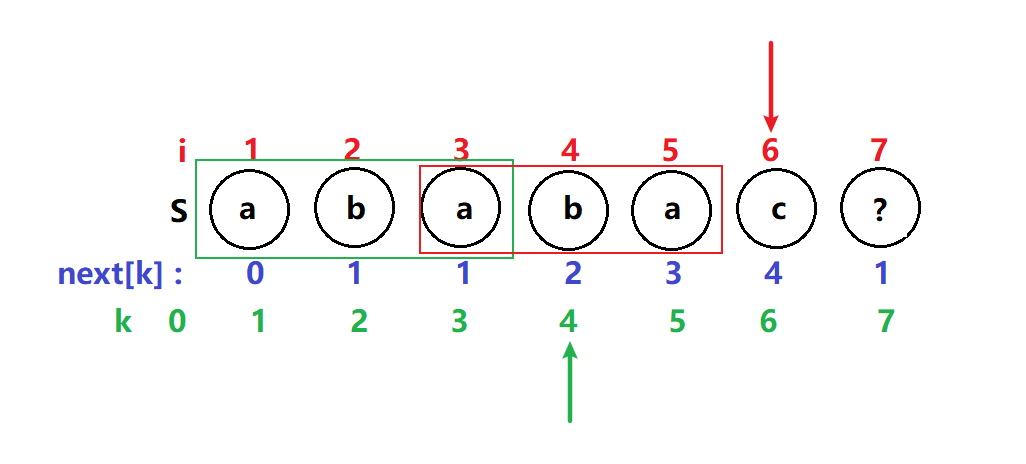
i 不变,k = 2 T[6] ≠ T[2] k指针继续回溯到next[k] =next[2] = 1
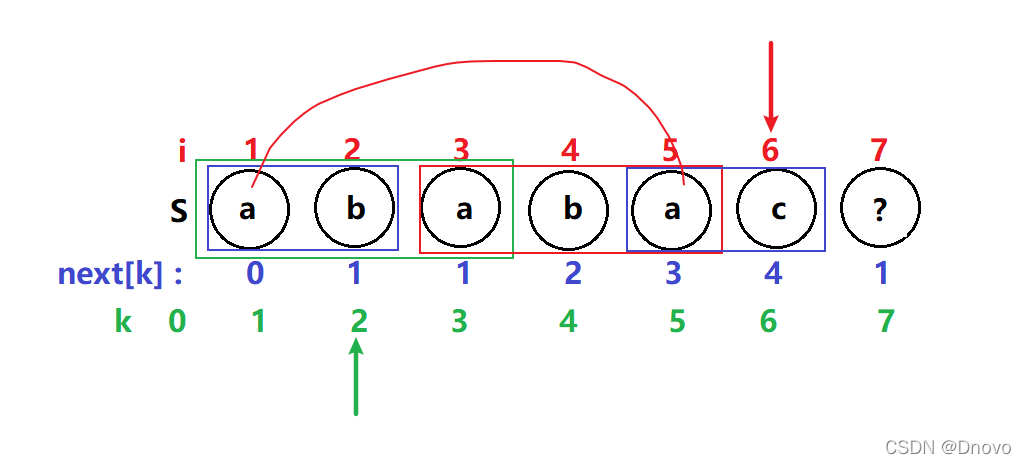
i 不变,k = 1 T[6] ≠ T[1] 这次匹配不成功则说明子串$P_{1}P_{2}P_{3}P_{4}P_{5}P_{6}$前后缀并不重复,于是k指针回溯到next[k] =next[1] = 0,进行i ,k指针后移比较下一个子串
我们再通过gif动画再来回顾一遍上面的流程:

主串和模式串的匹配
这一部分就比较简单
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
//返回子串T在主串S中第pos字符之后的位置,若不存在则返回0
//代码需要根据自己的索引值更改循环的边界
int KMP(string S,string T,int pos){
int i = pos;
int j = 1;
int next[255];---------------------------1
getNext(T,next);-------------------------2
while(i <= S[0] && j <= T[0]){
if(j == 0 || S[i] == T[i]){
++i;
++j;
}else{
j = next[j];---------------------3
}
}
if(j > T[0]) return i-T[0];
else return 0;
}
下面看两个例子

通过上面两个例子也可以看出KMP算法仅当模式与主串之间存在许多“部分匹配”和模式串前后缀相似度小的情况下才能体现它的优势,否则和朴素模式匹配差异并不明显